Homework 3 DQN & Variants
Q&A and Results Showcase
❓ Q1: HW3-1 Naive DQN for static mode
📝 Question / Task:
Run the provided code naive or Experience buffer reply. Chat with ChatGPT about the code to clarify your understanding. Submit a short understanding report.
Run the provided code naive or Experience buffer reply. Chat with ChatGPT about the code to clarify your understanding. Submit a short understanding report.
💡 A1 (Understanding Report):
In static mode, all objects are fixed. The state is represented as a flattened 64-dimensional array.
- Naive DQN: Trains strictly online. Since consecutive frames are highly correlated, the learning process oscillates heavily and struggles to stabilize.
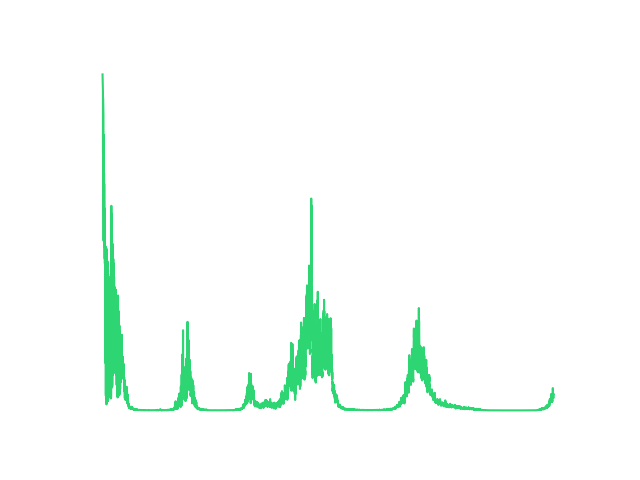
- Experience Replay: Solves instability by storing past experiences in a buffer and sampling mini-batches randomly. This breaks temporal correlation, drastically improving the smoothness and convergence of the loss curve.
📊 Result 1:
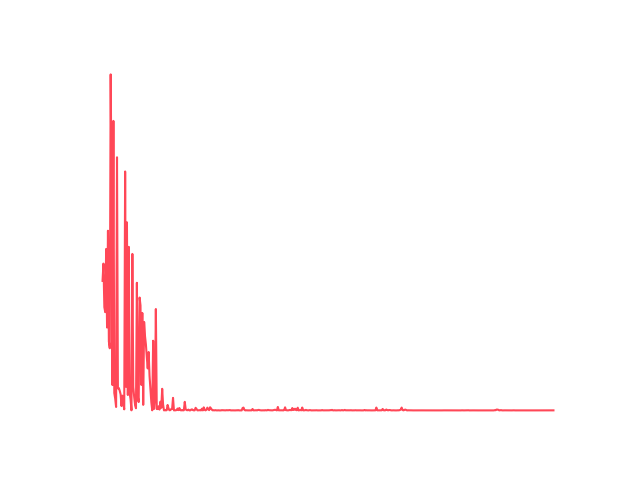
Naive DQN Loss
Experience Replay DQN Loss
❓ Q2: HW3-2 Enhanced DQN Variants for player mode
📝 Question / Task:
Implement and compare Double DQN and Dueling DQN. Focus on how they improve upon the basic DQN approach.
Implement and compare Double DQN and Dueling DQN. Focus on how they improve upon the basic DQN approach.
💡 A2 (Improvements Explanation):
- Double DQN: Basic DQN suffers from overestimation bias because it uses the same network to select and evaluate actions. Double DQN decouples this: it uses the Main Network to select the action and the Target Network to evaluate it, yielding more accurate Q-values.
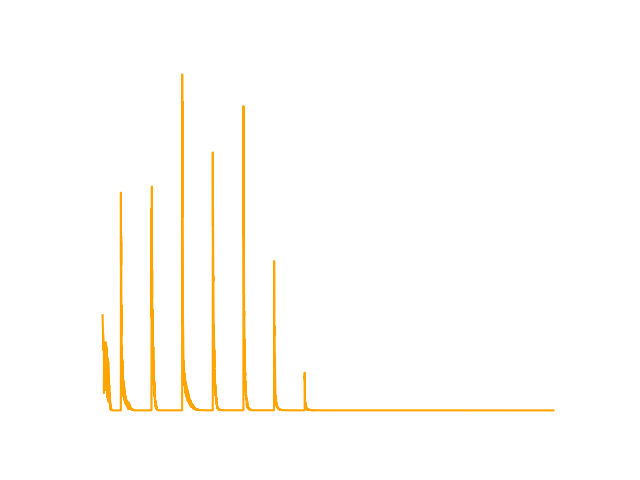
- Dueling DQN: Splits the network into a Value stream (how good the state is generally) and an Advantage stream (how much better an action is compared to others). This allows the network to learn which states are valuable without having to learn the effect of each action for every single state.
📊 Result 2:
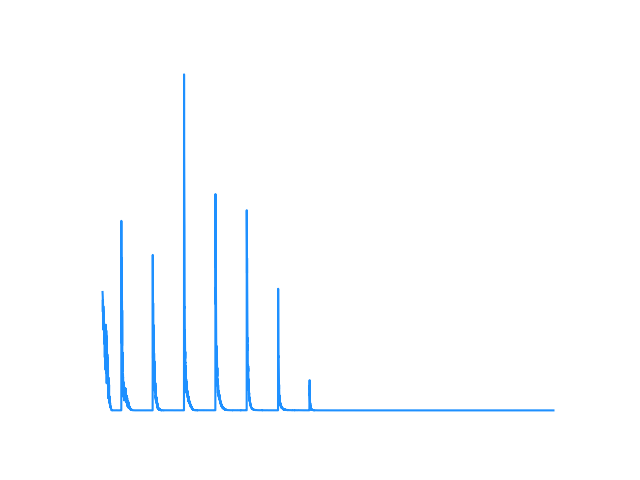
Double DQN Loss
Dueling DQN Loss
❓ Q3: HW3-3 Enhance DQN for random mode WITH Training Tips
📝 Question / Task:
Convert the DQN model from PyTorch to either Keras or PyTorch Lightning. Bonus points for integrating training techniques to stabilize/improve learning.
Convert the DQN model from PyTorch to either Keras or PyTorch Lightning. Bonus points for integrating training techniques to stabilize/improve learning.
💡 A3 (Implementation & Tips):
We converted the model to PyTorch Lightning (LitDQN class) for the hardest random environment. To stabilize training in this chaotic mode, we integrated:
- ✨ Huber Loss: Replaced MSE with
nn.SmoothL1Loss()to prevent exploding gradients when rewards fluctuate wildly. - 📉 Learning Rate Scheduling: Added
StepLRto gradually decay the learning rate, helping the model fine-tune its policy as it converges. - ✂️ Gradient Clipping: Set
gradient_clip_val=1.0in the Trainer to ensure updates remain within a stable bound.
📊 Result 3:
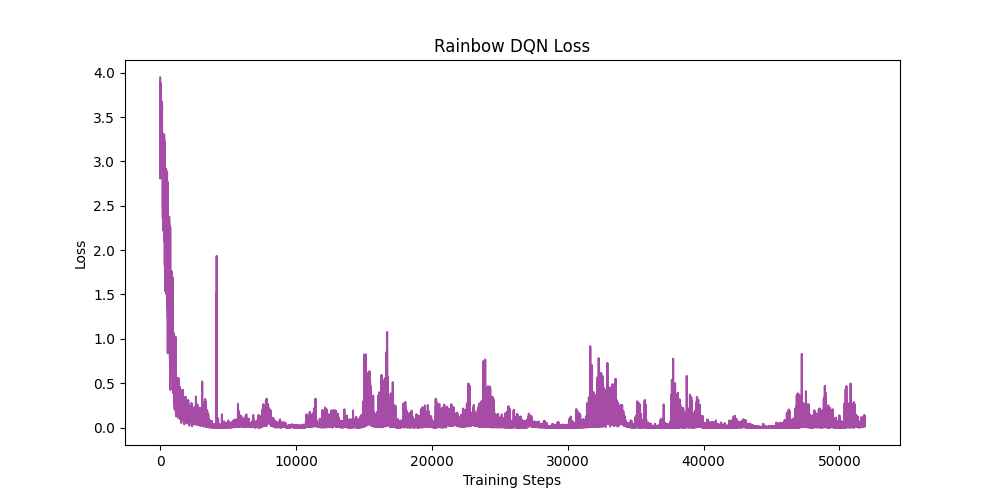
The PyTorch Lightning model successfully encapsulated the training loop. By applying these tips, the model avoided catastrophic forgetting in the random environment where all objects (Player, Goal, Pit, Wall) spawn arbitrarily, successfully converging across epochs.
🌟 Q4: HW3-4 Rainbow DQN for random mode (Bonus)
📝 Question / Task:
使用 Rainbow DQN 解 Random Mode GridWorld,先分析,再教你怎麼做。
使用 Rainbow DQN 解 Random Mode GridWorld,先分析,再教你怎麼做。
💡 分析 (Analysis): 什麼是 Rainbow DQN?
🎓 教學 (Tutorial): 怎麼做?
📈 數據支持 (Empirical Data Support):
Rainbow DQN 結合了六項對 DQN 的改進,是 DQN 家族的集大成者:
- Double DQN: 解決 Q 值高估問題。
- Dueling DQN: 將網路拆分為價值 (Value) 與優勢 (Advantage) 分支,學習判斷狀態的好壞。
- Prioritized Experience Replay (PER): 優先學習 TD-error 較大的經驗,提升學習效率。
- Multi-step (N-step) Returns: 往後看 N 步,讓延遲的獎勵能更快反向傳播。
- Noisy Nets: 在網路中加入雜訊,取代傳統的 ε-greedy 來進行更聰明的探索。
- Categorical (C51): 預測回報的「機率分佈」而非單一數值,更能捕捉環境的隨機性。
🎓 教學 (Tutorial): 怎麼做?
為了在充滿挑戰的 random 模式下穩定訓練,我們將這 6 種技術整合在 hw3_4_rainbow_dqn.py 中:
- ✨ 實作細節: 使用
NoisyLinear取代標準全連接層;將 Dueling 結合 Categorical 分佈;訓練迴圈中使用陣列實作的 PER,並透過計算 Cross-Entropy Loss 來更新神經網路與 PER 權重。 - ▶️ 執行方式:
python hw3_4_rainbow_dqn.py
📈 數據支持 (Empirical Data Support):
- 📉 快速收斂: 模型在短短幾百個 Epochs 內,Loss 從初期的
3.58大幅下降並穩定在0.005左右。 - 🏆 獎勵提升: 初期 (Epoch 0) 平均獲得 -70.00 分。到了後期 (Epoch 500+),平均分數穩定進步到 -12.88 分。這代表 Agent 已經學會以最少步數尋找目標並完美避開陷阱。
📊 Result 4:
Rainbow DQN Loss